


The end of 0% interest rates: what it means for software engineering practices
Could we see monoliths favored over microservices, full-stack tools over platform specific ones and pragmatic, simpler architecture as a response to 10+ years of 0% interest rates ending?

👋 Hi, this is Gergely with a subscriber-only issue of the Pragmatic Engineer Newsletter. In every issue, I cover challenges at Big Tech and startups through the lens of engineering managers and senior engineers. To get articles like this in your inbox, every week, subscribe:
This article is part 4 in a 4-part series on the end of 0% interest rates. Other issues cover:
What it means for startups and the tech industry (Part 1.) More pressure to achieve profitability, less venture capital funding, Big Tech gets bigger, and bootstrapping more common.
What it means for software engineers (Part 2.) A tougher job market, harder to negotiate offers, slower career growth, and higher performance expectations.
What it means for engineering managers (Part 3.) Fewer EMs, more responsibilities for the rest, the rise of the tech lead role, and an opportunity to build more cohesive teams due to lower attrition.
What it means for software engineering practices (Part 4, this one.) Monoliths over microservices, more shifting left of responsiblities and pragmatic, simpler architecture.
Before we start: The ebook version of my book, The Software Engineer’s Guidebook is (finally!) available on all major ebook platforms. Get it here. You can grab it on Kindle, as DRM-free ePub/PDF and on other popular ebook marketplaces. If you’re wondering what it’s like: here’s a recent book review from Sandor Dargo, Senior Engineer at Spotify.
A long period of zero percent interest rate policies (ZIRP) recently ended, after lasting nearly a decade and a half since the global financial crisis of 2007-2008. That ZIRP period also coincided with the smartphone and cloud computing revolutions. So far in this series analyzing what today’s post-ZIRP era means for tech workers, we’ve covered what a 0% rate era is, why it matters for tech, and also:
What it means for startups and the tech industry. More pressure to achieve profitability, less venture capital funding, Big Tech gets bigger, and bootstrapping more common.
What it means for software engineers. A tougher job market, harder to negotiate offers, slower career growth, and higher performance expectations.
What it means for engineering managers. Fewer EMs, more responsibilities for the rest, the rise of the tech lead role, and an opportunity to build more cohesive teams due to lower attrition.
We wrap up this important topic with a focus on software engineering practices, and what to expect in how most companies build software in future. Today, we cover:
Monoliths favored over microservices? Microservices are a great tool to prepare for hypergrowth in headcount. But do we even need them when growth is slow, or perhaps even negative?
Full-stack and cross-platform push. Engineering teams where with full-stack engineers, using cross-platform frameworks get the same stuff done with fewer people, with slightly less polish. That “less polish” is harder to notice: but the smaller team size means faster iteration and lower overall cost that are both harder to ignore.
Pragmatic, simpler architecture. During ZIRP, it made sense to solve problems the engineering team doesn’t yet have, but will have in 6-12 months. With ZIRP behind us, this could be a more wasteful approach. Why not solve architecture issues when teams feel the pain of the current architecture slowing things down too much?
More responsibilities “shift left.” Developers end up taking on more responsibilities on DevOps, security, infra and platforms. All this comes with better tools to be able to manage all this – and, at larger companies, centralized security and platform teams supporting engineers.
Buy vs build vs use open source. Building non-core tools in-house will make much less sense, when looking at the numbers – especially if Section 174 tax changes stay in place. A more common question will be to buy from a vendor, or operate an open source solution instead?
Commercial backing for the most popular open source projects. The open source field will almost certainly shift: community funded open source projects could see fewer companies contributing, while some of the widely used – and well-supported – open source projects will likely see licenses become more restrictive.
Other industry observations. Less focus whether engineers enjoy working on a project; serving sales teams becomes more important; less tech debt and more business priorities focus, amongst others.
1. Monoliths favored over microservices?
One of the 2010s’ biggest architectural innovations was microservices. The first conference talks to mention this term were in 2012-2013, and Martin Fowler and James Lewis wrote an in-depth guide about the new approach in 2014.
Uber was a well-known scaleup at the time which adopted and popularized microservices, extensively writing about it in engineering blogs, and giving talks; for example, “What I wish I had known before scaling Uber to 1,000 services” by Matt Ranney.)
Others followed and created thousands of microservices. In the UK, neobank Monzo embarked on this journey in 2015, and cofounder Tom Blomfield kicked it off with this Slack message:

In 2024, we know the “???” in his message means “wait a long, long time.” It took Monzo 8 years to get from “2. Microservices,” to “4. Profit,” when it enjoyed its first month in the black in May 2023, after Blomfield had left the company.
Microservices have been a Band-Aid for hypergrowth, and it’s unclear if they have uses beyond this. I was at Uber during the rapid growth of services, and their subsequent “taming,” so I have thoughts about the good and bad of microservices, and why Uber was better off for using them when it did.
The good:
Revealed engineering teams and orgs with zero alignment. Really! Every team builds their own stuff, and may be blissfully unaware of what others do. At Uber, this approach made sense initially, when there were nearly a dozen internal “startups” like Rides, Driver, Eats, Rush, Air, China, ATG and others at work.
Fewer meetings between teams. Instead of scheduling a meeting with a team on how to integrate your functionality into a service owned by another team - and the inevitable negotiations, waiting on the other team, and so on - you just build a new service, not needing to coordinate with other teams.
You can start teams with less experienced engineers. A new team has few users, so it’s not the end of the world if their services aren’t so stable. Less experienced engineers learn the ropes and improve through trial and error, and outages.
The bad:
Duplication of work and services. Lots of services do similar things, and at first this isn’t an annoying problem. But over time, it can become a source of constant frustration when a team builds yet another microservice to unblock itself, rather than taking a day or two to integrate their use case to a service that otherwise perfectly fits their needs.
Tooling challenges. When you have thousands of services, simple questions like who is oncall for a service, the location of a service’s code, and how to deploy a service, become more complex. Integration testing of multiple services is non-trivial. Testing in production becomes more of a necessity than a choice, because maintaining a test environment for so many services is unfeasible in resource and complexity terms.
Oncall hell for teams. When a team with 7 engineers operates 20 services, oncall is often stressful and hard to manage.
An outstanding short summary of microservices’ downsides is in “Microservices,” a comedy sketch by KRAZAM:

Every organization that’s all-in on microservices must deal with challenging downsides. The benefits of microservices matter during hypergrowth, but not when the engineering organization stops doubling in size, annually. Then, it makes sense to consolidate services and use a more sensible services strategy.
In 2020, Uber announced a domain-oriented microservice architecture to reduce systems’ complexity. This approach wrapped dozens of microservices into a single “domain,” to reduce the number of communication surfaces, while teams migrated small services into larger, “well-sized” services.
In 2022, Monzo shed light on the tooling pain of managing 2,500 services. The online bank is investing in more tooling to overcome these issues.
Monoliths can mean a safer bet when growth isn’t expected. The upsides and downsides of monolith services are the opposite to those of microservices. Monoliths do poorly when you onboard a large number of new engineers, because everyone is stepping on each other’s toes. But they work well when there’s a good rhythm of development and deployment, so long as the team doesn’t grow too fast.
Stripe is in the middle of breaking up its monolith into larger services, while elsewhere, Shopify modularized its Ruby on Rails monolith. These companies prove that starting out with a monolith, and then breaking it into smaller chunks as you grow, is a viable option during rapid growth.
I’m hearing more accounts of the pain of having too many microservices after deep cuts. A Fintech that employed 8,000 staff at its peak, including 2,000 engineers, did mass layoffs and brought headcount down to around 5,000, with engineering below 1,500. Today, microservices are a big operational problem. From an engineer at this company:
“We still have around ~2,000 services to take care of, even though we now have less than 2/3rds of the engineers we had in 2021, when we built all of these! We recently told leadership: “We don’t have enough people to even operate these services: we need to hire more.” The response has been: “Sort it. Maybe use AI?”
Of course, nobody should optimize for laying off 40% of staff, but companies with simpler architectures see operational overhead as less of an issue when there are fewer staff, than places with thousands of microservices do.
To be clear: a system that keeps growing will always come with headaches, and modularizing a monolith is challenging – as is breaking it up. Khan Academy spent 3.5 years on breaking up its monolith into several services. But introducing more complexity when there is a pressing need, could be a more pragmatic approach than starting with a complex setup with potentially hundreds of microservices.
We should not fully discount the evolution of microservices tooling, though. One thing that a decade of microservices has resulted in is far better tooling to build, operate and manage microservices than in the early 2010s.
Developer portals like Backstage offer service catalogs to locate services — and support even thousands of these — and there are hundreds of startups building tools to manage microservices at scale. While starting with microservices might not be optimal for most startups these days: transitioning to them — for companies that verbalized the benefits they will get — is less risky: tooling is better, and there are fewer “microservices unknowns” that have not been talked about.
2. Full-stack and cross-platform push
Take a hypothetical product which needs to work the same on the web, iOS, and Android, and two teams are building their own versions of it:
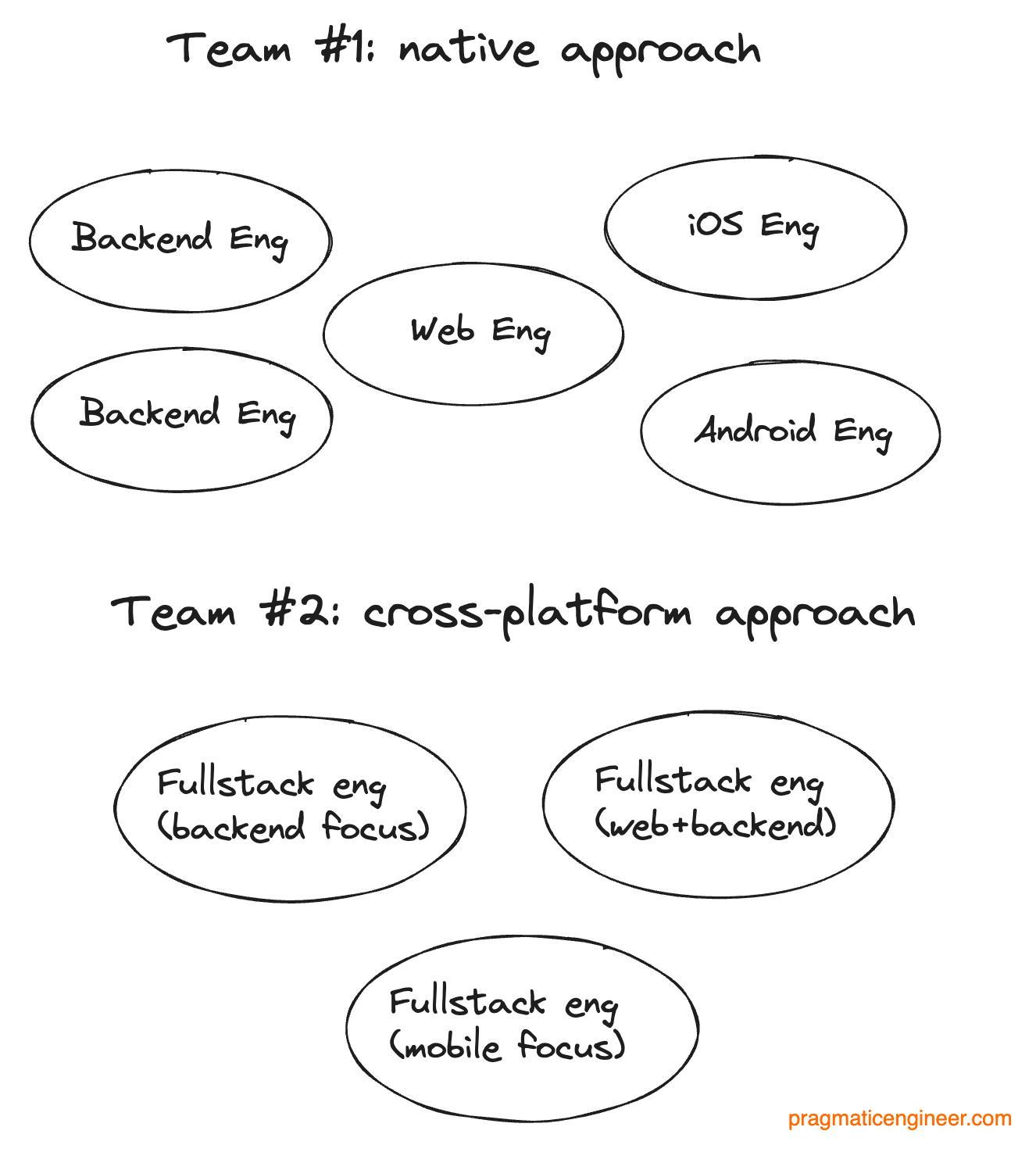
Team #1 chooses this stack:
Backend: Go
Web: React + TypeScript
iOS: native (Swift)
Android: native (Kotlin)
Team #2 consolidates and uses:
Backend: Node/TypeScript
Web+mobile: React + React Native + Expo / TypeScript
Team #1 needs to hire at least 4 engineers, but in reality this usually ends up being 2 backend engineers because the backend must support endpoints for 3 apps: web, iOS, and Android. Meanwhile, team #2 needs only two full-stack engineers for focusing on the services side, and the client side. So, three engineers should be more than enough.
Team #2 might even be able to move faster than Team #1 because everyone uses the same stack. On Team #1, the iOS engineer likely will wait on the backend engineer to make a change in the Go service, whereas on Team #2, the frontend and backend are both in TypeScript.
Eighteen months ago, I asked if there was a drop in native iOS and Android hiring at startups: and concluded that there appeared to be. This trend is only accelerating as cross-platform solutions like React Native, Flutter and Expo allow the shipping of native apps that are increasingly hard to distinguish from actual native-built apps. And this affects engineers: most software engineers Stripe hires are fullstack; backend and frontend-only engineers are rare.
3. Pragmatic, simpler architecture
An engineering manager at a scaleup that’s cutting headcount from 150 to circa ~80, shared:
“I believe ZIRP led to a lot of overcomplicated tech architectures; byzantine microservice architectures and multiple databases, where a simple monolith with PostgreSQL as a database would have been enough. It inevitably led to unsustainable headcount in engineering departments as well. I expect this excess to reduce by a lot.“
“I see a change in developers around me, who’ve started to talk a lot more about pragmatic and efficient architectures, and a lot less about ‘best’ tools for the job.”
Architecting to solve a current pain point could become more common. During times of fast growth, it makes a ton of sense to design systems for future expected loads, even if they fail to materialize.
For example, this approach was why Fast hired so many software engineers, who built state-of-the-art payments systems capable of processing billions in currency. A good part of the engineering team had built these types of systems before; including on Uber’s payments team.
For Fast, the issue was that it processed around $30M annually at its peak, which was far less than the billions its complex systems were built to handle. The business was ambitious to rapidly sign up merchants, and optimistically predicted it would process $1.6B in 2022. Instead, the business shut down that year. It’s possible that Fast would have had more time to achieve a viable business model had it not burnt through $100M, mostly on salaries. We cover Fast’s unceremonious downfall in Inside Fast’s rapid collapse.
Looking ahead, I expect CTOs, engineers, and non-technical decision makers to be a lot more conservative. Instead of investing as much time, money, and energy, to build a system that can handle 100-1,000 times more than is actually processed, maybe they’ll just build something that’s good enough.
Back in 2016, Stack Overflow served 209M daily requests and 1.24TB of daily data, sent via a surprisingly barebones stack of 23 servers (11 web, 4 SQL, 3 Elasticsearch, 3 tag engines, 2 Redis,) 4 load balancers, 4 routers, and 2 firewalls. All this was hosted in data centers without utilizing the cloud, and running what was then one of the top 300 websites, globally!
Frameworks allowing for “one-person teams” could see more adoption. Companies with budget for just one developer will ask if a single software engineer can build the same product which Teams #1 are #2 built in the example above. If such a framework exists, they will surely choose it.
There’s a lot of technological challenges in a framework that works well enough on backend, the web, iOS, and Android, but it should be doable. Basecamp cofounder David Heinemeier Hansson (DHH) created Ruby on Rails to make it possible for one developer to build both backend and frontend – and he arguably succeeded. Two years ago, he wrote that a “one person framework” could be close with Rails 7:
“A toolkit so powerful that it allows a single individual to create modern applications upon which they might build a competitive business. The way it used to be.”
There are tradeoffs in frameworks that abstract away the complexity of the several underlying platforms they generate for. They are necessarily opinionated, and it can be hard to make custom changes to a single platform. This tradeoff is one which smaller teams may be inclined to take, if it means they can ship to several platforms faster, on a budget.
Architecture strategies will likely mirror hiring strategies more closely. An interesting observation about bootstrapped – thus slower growth – companies was this:
Bootstrapped companies grow much, much slower. They don’t hire ahead, and only hire when they feel the pain of having too few people, and a hire is justified.
As more companies will likely adopt the strategy of hiring when they feel the pain of having too few people: I expect more engineering teams to make architecture changes not ahead of time but when they feel the pain of the current architecture slowing them down too much.